Google Wave is a great leap forward in user experience. It attempts to answer the question ‘what would email look like if it was invented today’. It, however, started from a clean slate, which I am not sure we need to do. I think we need to look at the kind of collaborations now taking place on the internet and look at streamlining their user experience. Given the spread of social sites and the volume of data exchanged within them it seems to make sense to look at those for some inspiration on how to reinvent / tweak email.
A lot of the social sites allow for collaborations and provide a notifications when a collaboration within the site has taken place e.g. a status updated, or a status commented on or a photo shared. Most of them send you an email with a link. Something like this.
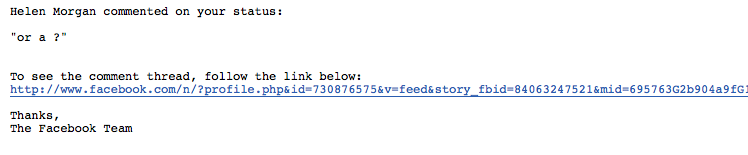
You click on the link, then you login and finally you get to respond, at which point more emails are sent out to other participants, who all open emails, click links and login and around and around we go. The important point here though is that the social site maintains a single copy of the collaboration and makes it available via a url. Contrast this to collaborating in email.
Email today shunts around copies of html documents for collaborations. It does this as there have been historical constraints that make this the only practical design. The big two constraints were intermittent connectivity to the internet and a lack of single sign on for the web. The last point is not immediately obvious as something email addresses. It achieves it though by sending and then storing a copy of the collaboration in a store that the recipient is authorized to view. Its advantages becomes glaringly obvious when you try and share photos privately for the first time with your mother via facebook. The set of steps required for her to sign up, choose a password, etc. quickly become too tedious and cumbersome to make this a universal approach.
Both of these design constraints are however disappearing. Netbooks from cell phone companies and recent announcements from airlines make ‘always connected’ a reality and openid and oauth momentum, which both have a role to play in web single sign on, seems unstoppable. Openid has also recently been paired nicely with oauth and has had some nice usability improvements.
In addition to these design constraints disappearing another shift makes a rethink timely.
Email as a Service – Most of us are now getting email from a web site e.g. gmail, hotmail, yahoo. As this is a service in the cloud any data that I have in the service is available for integrations, e.g. it can provide a standard api for getting at contact data which is a big deal. In addition it can provide many other services for third parties to integrate with (more on this later).
My previous post claims that we should start to think about sending something other than html to each other over SMTP. This post will walk through what sharing photos with my mother could look like if facebook sent an atom entry instead of html with a link and if gmail understood how to interpret the atom entry. The main goal will be to provide an approach that my mother can use.
Here’s a possible step by step
1. I share a facebook private photo album with my mother by just entering her email address.
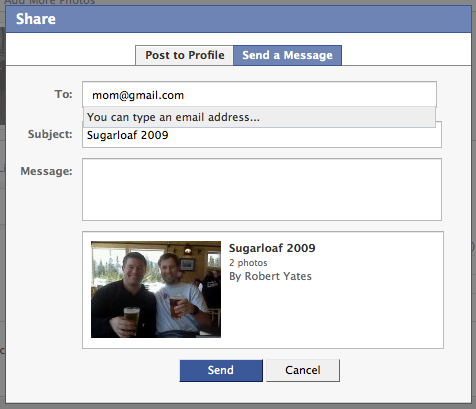
2. Facebook sends an email to my mother that also contains an Atom Entry as below (note that this can be in addition to the normal text and html representations all bundled up in a mulipart message)
<entry>
<title>Rob has shared the album Sugarloaf 2009 with you</title>
<link href="http://facebook.com/photo.php?id=8237298723&mode=preview&email=mom@gmail.com&oid_provider={oid_provider}"/>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2009-06-13T18:30:02Z</updated>
<summary>Rob wants to share the album Sugarloaf 2009 with you.</summary>
</entry>
Note also that the link utilizes uri templates. This is needed so that facebook can be passed the user’s openid provider’s endpoint by the email service.
3. My mother (who uses gmail for her mail) logs in and sees that she has an email from facebook stating that I have shared an album with her. She opens the ’email’. Gmail spots that the email contains an atom entry, extracts the link href, substitutes in the url for google’s openid endpoint and opens the web page within the mail client (probably in an iframe). My mom just thinks she opened an email.
4. Facebook now needs to work out who the user at the browser is. It already knows that the user at the browser is associated with the email address mom@gmail.com as it embedded this in the atom entries link url sent to her in the email (this is similar to the way that most web sites validate ownership of an email i.e. those ‘We just sent a confirmation email to you, please click the link…..‘ kind of things). Facebook now just needs to get my mom’s openid, associate it with her email and my mom can then automagically become a facebook user with an account that has access to the shared photos. So.
5. Facebook redirects to mom’s openid provider (which is google) and which was provided to facebook in the url. It does this from inside the iframe, so as far as my mom is concerned this is all taking place inside her email service. The redirect probably uses html fragments so that the context is not lost and it is implemented very much like the openid ui extension except it is both the RP and OP that use fragments. This redirect causes gmail to pop up a box that asks my mom’s permission to share her name and email with facebook.
6. My Mom grants permission causing a redirect back to facebook (in the iframe) passing back to facebook her openid, name and email. Facebook now sets up a new account for my mom associating my mom’s google openid with her email mom@gmail.com. Again as far as my mom is concerned all this is taking place within the email service. She has never left her inbox.
7. Mom now sees the message open and sees my photos rendered live from facebook in the message pane. If there has been any updates to the photos or comments she sees all of them. Mom can now also post comments on the photos in the iframe rendered right inside gmail, before moving onto her next message.
If I now share subsequent photos with her via facebook then the same dance occurs when my mom opens the message, but this time google no longer needs to ask for my mom’s permission to send along her openid so as far as she is concerned the photos delivered straight from facebook open up right inside her email client.
There are probably many services that would benefit from this kind of email integration. Facebook, flickr, evite and google groups spring to mind as does my current defect tracking system which I am sick of logging into :)
There are lots more variations on this theme. The atom entry can contain mulitple links, one could be for preview, one could be for full screen, the links could even represent REST services that would allow programatic access to the data from the email service. In addition the modified timestamp along with the id field in the atom entry can be used by the mail server to ensure that you only see the latest update and don’t have to wade through 12 emails of updates for the same thing. As a final thought a gadget xml could be sent in atom entry content section. There are a realm of possibilities, but it all begs the question, why are we still sending each other html?
