Jason Grigsby : It seems like a basic concept, but the fact that links can only reliably open web pages is often forgotten.
mobile first and yiibu
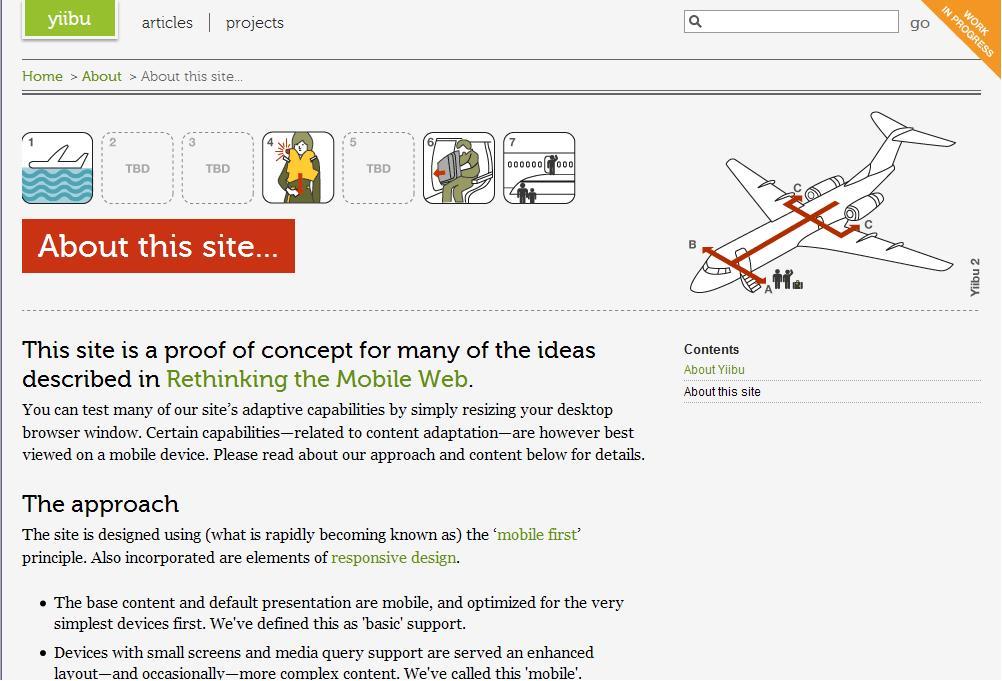
yiibu.com: This site is a proof of concept for many of the ideas described in Rethinking the Mobile Web. You can test many of our site’s adaptive capabilities by simply resizing your desktop browser window. Certain capabilities—related to content adaptation—are however best viewed on a mobile device.
The site is well worth taking a look at (make sure to resize your browser to test it out). It shows how it is very possible to design a single set of pages that render one way on a large screen and a different way on a smaller screen.
It goes from this
To this
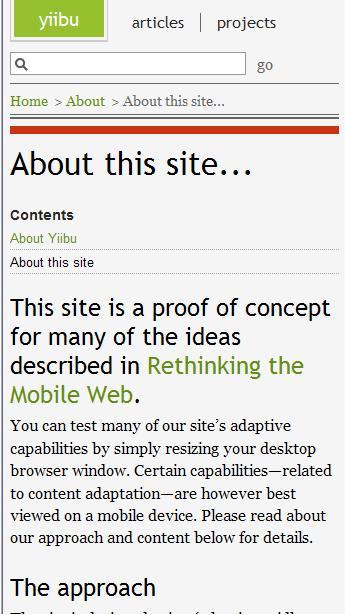
Very Cool
PIE – Progressive Internet Explorer
Compass, Blueprint and IE6 text alignment
Lately I’ve been playing with compass, a SaSS mixin which is derived from blueprint. Things were working quite nicely with my testing in ff and safari, but in IE6 all the text was centered. It takes some digging in compass to understand why this happens so to save others time.
Do this
<div class="container"> ... </div>
and not this
<div id="container"> ... </div>
Wave Goodbye
LLVM 2.7
LLVM continues it’s quiet ascent. It now has two jdks, two clis, python (and by that I mean the real python), ruby and php running on it. Not bad for a compiler / runtime who’s main goal is to be apple’s main compiler for static languages (C, C++ and Objective C).
Ignore at your peril.

WebFinger, OAuth and Freebusy lookups
One of the more frustrating aspects of calendaring systems is that the freebusy lookups are all proprietary. Meeting invitations can be sent from one system to another (assuming you know a time to meet). However, it is not possible to lookup when someone from Lotuslive, someone from gmail and someone from Yahoo are all available to meet. In the corporate space this type of scheduling is invaluable.
The format for looking up someone’s freebusy time is included in a standard that was completed in 1998, but they punted on all the hard stuff. The hard bit, as I have mentioned before, is working out where someone’s freebusy is stored on the web and then authenticating with that store in a manner that can be verified. WebFinger and OAuth are now putting the complete round trip within spitting distance.
Below I’ll propose an approach to scheduling a meeting with my mom (who uses gmail) from LotusLive (which I use). I will be rob@robubu.com (but using LotusLive for my calendaring service) and my mom is mom@gmail.com. We’ll also assume that my mom has told google that it can share her calendar free time data with any one in her contact list and that I am in her contact list.
- I head into my calendar service (on lotuslive), click on Add Event and type mom@gmail.com into the invitees list.
- LotusLive now uses WebFinger to lookup the different api services that google provides for access to my mom’s data along with the corresponding URL for the service. The details on how this works are outlined here on Eran’s blog. At the end of this, LotusLive gets back a XRD document that looks something like the following.
<?xml version='1.0' encoding='UTF-8'?>
<XRD xmlns='http://docs.oasis-open.org/ns/xri/xrd-1.0'>
<Subject>acct:mom@gmail.com</Subject>
<Alias>http://www.google.com/profiles/mom</Alias>
<Link rel='http://portablecontacts.net/spec/1.0'
href='http://google.com/api/people/' />
<Link rel='http://ietf.org/icalendar/freebusy'
href='https://google.com/api/calendar/mom/freebusy/' />
</XRD>From this LotusLive can now determine that my mom’s freebusy endpoint is at https://google.com/api/calendar/mom/freebusy/. It concludes this by looking for the link with a rel attribute of http://ietf.org/icalendar/freebusy
- If my mom had made her freetime calendar data public then LotusLive can simply retrieve the data from the URL, but to add to the complexity let’s assume that it requires authentication i.e. LotusLive needs to prove to Google that it has rob@robubu.com at the browser and then Google checks that rob@robubu.com is in my mom’s contact list. We’ll do something here very similar to what signed fetches do in opensocial i.e. lotuslive will use OAuth to assert that it has rob@robubu.com at the browser. What we’ll end up with is a url that looks something like
https://google.com/api/calendar/mom/freebusy/
?opensocial_viewer_id=rob@robyates.com
&xoauth_public_key=https://lotuslive.com/keys/publickey.crt
&oauth_signature_method=RSA-SHA1
&oauth_signature=djr9rjt0jd78jf88%26jjd99%2524tj88uiths3
LotusLive has here claimed that it has rob@robubu.com at the browser and using OAuth has signed the request with a private key. It has also indicated where the public key is to validate the signature. - Google receives the request, retrieves the public key and verifies the signature. If it trusts signatures and keys from LotusLive (verifiable by retrieving certs from an https url with a lotuslive.com domain) then it is done at this point. However that is a fairly large amount of trust to place on LotusLive as LotusLive could assert on behalf of any identity. Google really needs to check that LotusLive can assert rob@robubu.com’s identity. Here we’ll use webfinger again.
- Google now does a WebFinger lookup on rob@robubu.com and gets an XRD document such as the one below
<?xml version='1.0' encoding='UTF-8'?>
<XRD xmlns='http://docs.oasis-open.org/ns/xri/xrd-1.0'>
<Subject>acct:rob@robubu.com</Subject>
<Link rel='IDP' href='https://lotuslive.com' />
</XRD>
Google now sees that lotuslive.com is a valid Identity Provider for rob@robubu.com and so accepts the assertion. - Google checks that rob@robubu.com is in my mom’s list of contacts and as I am returns her freebusy.
- Finally, LotusLive gets a response from Google outlining my mom’s free time and displays it in a nice calendar. I can choose a time that she is free and send her an invite.
I know this is not perfect and I know there are probably a fair amount of changes that are needed, but I wanted to jot down something that, I think, is fairly close to a workable solution. Am very interested in other’s thoughts.
p.s. WebFinger on email addresses does provide a means of discovering valid email addresses, but no where near as much as this does. The fight against spam can’t center on not making email addresses discoverable.

Hardware assisted virtualization – aka xen, kvm and ec2
Hardware-assisted virtualization: Hardware-assisted virtualization was first introduced on the IBM System/370 in 1972, for use with VM/370, the first virtual machine operating system. Virtualization was eclipsed in the late 1970s, with the advent of minicomputers that allowed for efficient timesharing,
George Santayana: Those who cannot remember the past are condemned to repeat it
My first I.T. job right out of university was as a DBA on an IBM mainframe for a large british retailer. That mainframe ran at near 100% cpu all day. The thing was amazing. It ran lots of different workloads. It ran web like applications (CICS). They got the highest priority and response times were great. Any spare capacity was devoted to batch jobs. This could be batch jobs that the business needed or it could be the developers submitting compilation jobs for code they were developing. The point is that it managed this mix of workloads beautifully, it ensured that the interrupt end user driven transactions got the priority and it soaked up any spare capacity with batch jobs that could be swapped in and out at will. Which brings me to the cloud.
There are many reasons that folks are advocating the cloud, but the most important would seem to be cost savings. The case is made in detail in this Booz Allen Hamilton paper which has this eye popping assumption that all the cost savings in their model are based on “Our analysis assumes an average utilization rate of 12 percent of available CPU capacity in the status quo environment and 60 percent in the virtualized cloud scenarios“. I’ve done a bit of digging and those two numbers seem to represent reality which is mind blowing to me on both fronts. The average server utilization in data centers today is a meager 12%, which is terrible and means that a bunch of servers are sitting there with apps that hardly anyone uses or apps that are seasonal and so most of the time aren’t hit. It also is surprising that they only assume 60% utilization in the virtualized cloud environment. Given that the mainframe could crank at 100% all day why isn’t that number higher?
I am speculating now, but I assume it isn’t higher because they are factoring in a significant overhead to hardware-assisted virtualization (like the kind that powers ec2). The very same overhead that caused hardware-assisted virtualization to get eclipsed, in the late 1970s, by computers that could do much more efficient time sharing and hence save a tonne of money. The key questions for anyone investing in building cloud infrastructures is whether economic factors will again render this technology obsolete and whether there is something that has similar characteristics but without all the overhead? Something that say could run 1000 linux instances on a single host? It’s not even the only game in town.

Amazon EC2 Spot Instances
Werner Vogels: Today we launched a new option for acquiring Amazon EC2 Spot Instances Using this option, customers bid any price they like on unused Amazon EC2 capacity and run those instances for as long their bid exceeds the current “Spot Price.” Spot Instances are ideal for tasks that can be flexible as to when they start and stop.
Spot Instances are ideal for Amazon EC2 customers who have workloads that are flexible as to when its tasks are run. These can be incidental tasks, such as the analysis of a particular dataset, or tasks where the amount of work to be done is almost never finished, such as media conversion from a Hollywood’s studio’s movie vault, or web crawling for a search indexing company.
There’s a whole class of applications that this is a game changer for. It will be interesting to follow its adoption.